第一章 绪论
The code in the book can be found from github: https://github.com/ocrbook/ocrinaction
❤ OCR conference:
dataset links
- DIBCO 2009 Dataset
- DIBCO 2010 Dataset
- DIBCO 2011 Dataset and Evaluation Tool
- DIBCO 2012 Dataset and Evaluation Tool
- DIBCO 2013 Dataset and Evaluation Tool
- DIBCO 2017 Dataset and Evaluation Tool
- H-DIBCO 2014 Dataset and Evaluation Tool
- H-DIBCO 2016 Dataset and Evaluation Tool
- H-DIBCO 2018 Dataset and Evaluation Tool
❤ OCR相关术语:
- DAR(Document analysis and recognition 文档图像分析和识别)
- STR(Scene text recognition 场景文字识别)
❤ Traditional OCR procedure
❤ 文字识别复杂性体现
自然场景图像的信息更加丰富,具有极大的多样性和复杂性。比如说,文字可能来自不同的语言,在每一种语言下,可能还包含多种字母。每种字母又可以有不同的大小、字体、颜色、亮度、对比度等。同时,文字的排列和对齐方式也不尽相同,横向、竖向、弯曲的情况都有可能。图像的非文字区域可能有与文字区域相似的纹理,比如窗户、树叶、栅栏、砖墙等。因为拍摄角度的问题,图像文字还存在形变问题(透视变换、仿射变换等)。此外,光照、低对比度、模糊断裂、残缺文字等也提升了文本检测和识别的难度。 (参考:https://book.51cto.com/art/202103/652750.htm)
但是深度学习OCR方法将简化整个流程为字符检测和字符识别两部分。
字符识别综述参考文章:
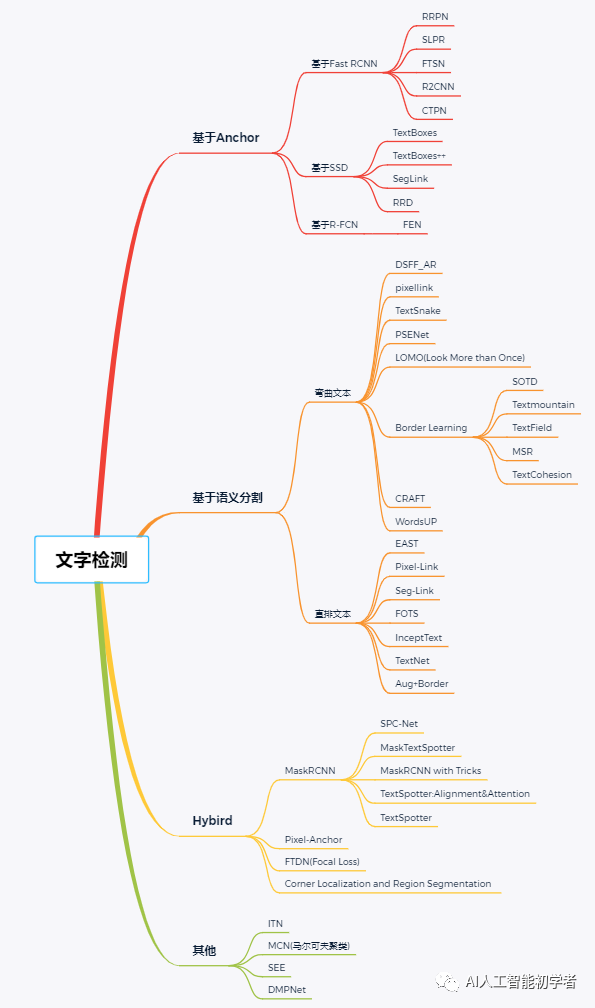
文字检测
- 基于候选框的文本检测:首先预生成若干候选框,然后回归坐标和分类,最后经过NMS得到最终的检测结果;
- 基于语义分割的文本检测:首先通过FPN直接进行像素级别的语义分割,然后进行后处理得到相关坐标即可;
- 基于上述2种方法的混合方法:混合实现;
- End-to-End方法:主要包括:FOTS、TextSpotter等,因为识别网络可以帮助检测网络去除一些非文字区域。
文字识别
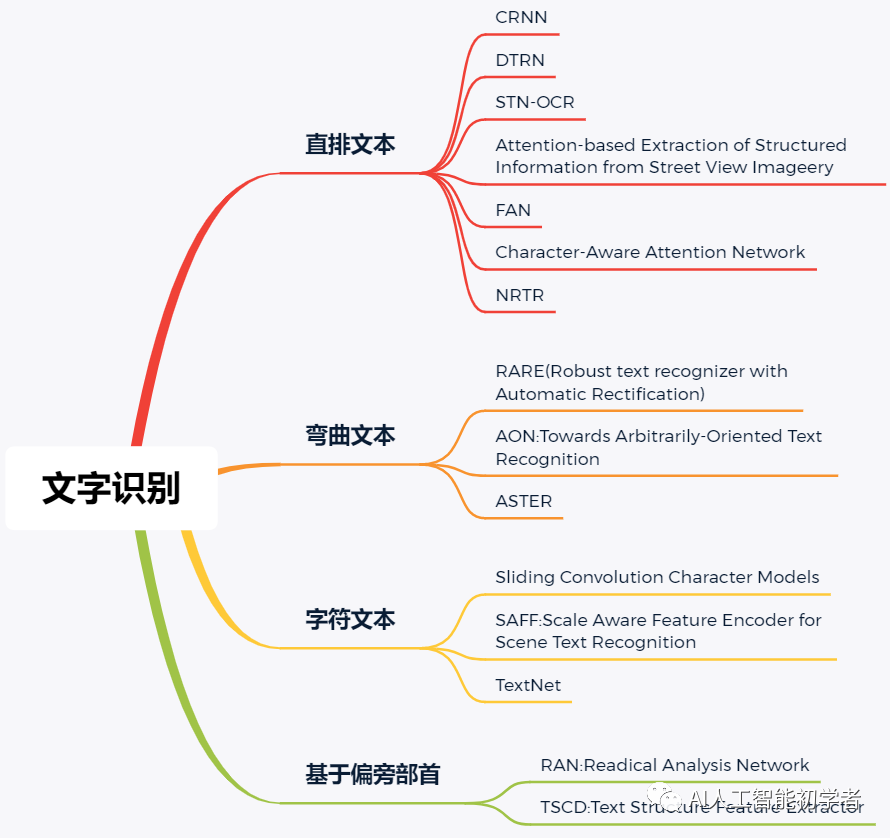
文字识别的目标是对定位好的文字区域进行识别,主要解决的是将一串文字图片转录为对应的文字的问题;常用的文字识别框架主要有2个:CNN+RNN+CTC和CNN+Seq2Seq+Attention:
- CRNN是白翔教授提出的End-to-End的方法,是目前主流的图文识别模型,可以识别比较长的而文本序列,包含CNN特征提取层和BiLSTM序列特征提取层,能够进行端到端的联合训练。同时,CRNN利用BiLSTM和CTC-Loss学习文字的上下文关系,从而提升了文字的识别率,使得模型更具鲁棒性。
- CNN+Seq2Seq+Attention相较于CRNN的区别是使用了Seq2Seq+Attention,可以用于解决多对多的映射问题,同时利用最新的Attention技术,提升了文字的识别率。Attention在英文识别上效果非常好,但是中文识别效果不仅不稳定而且算力开销大,所以工业界还是使用CTC更多一些。
产业应用
- 卡片证件识别类:身份证识别、银行卡识别、驾驶证识别、行驶证识别、港澳通行证识别、护照识别、户口簿识别、营业执照识别;
- 票据类识别:增值税发票识别、支票识别、承兑汇票识别、银行票据识别、营业执照识别、物流快递识别;
- 文字信息结构化视频类识别:主要有字幕识别和文字跟踪;
- 其他识别:二维码识别、一维码识别、车牌识别、数学公式识别、物理化学符号识别、音乐符号识别、工程图识别、流程图识别、古迹文献识别、手写输入识别;
- 除了以上列举的之外,还有自然场景下的文字识别、菜单识别、横幅检测识别、图章检测识别、广告类图文识别等围绕审核相关的业务应用。
第二章 图像预处理
介绍图像预处理中的二值化、去噪和倾斜角检测校正的常用算法,并于实战部分依据实例对比不同方法的去噪效果。
全局阈值方法
- 固定阈值方法
- Otsu 算法(又称最大类间方差法,是一种自适应的阈值确定方法)
局部阈值方法
- 自适应阈值算法:用到了积分图(Integral Image)的概念,它是一个快速且有效地对网格的矩形子区域计算和的算法。积分图中任意一点的值是从图左上角到该点形成的矩形区域内所有值之和。
- Niblack算法:根据窗口内的像素值来计算局部阈值的,它不仅考虑到区域内像素点的均值和方差,还考虑到用一个事先设定的修正系数k来决定影响程度。Niblack算法的缺陷一方面在于滑窗会导致在边界区域的像素范围内无法求取阈值;另一方面在于如果滑窗内全部是背景,那么该算法必然会使一部分像素点成为前景,形成伪噪声。因此,窗口尺寸r的选择非常关键,若窗口太小,则不能有效地抑制噪声;若窗口太大,则会导致细节丢失。
- Sauvola算法:是针对文档二值化处理,是在Niblack算法基础上的改进。Sauvola 算法在处理光线不均匀或染色图像时,比 Niblack 算法拥有更好的表现。
基于深度学习的方法
数据集
- DIBCO(Document Image Binarization Contest)于2009年首次举办,作为第一个国际文档图像二值化比赛,其目的是记录当前文档图像二值化领域的最新发展,并公开反映benchmarking数据集在图像二值化领域面临的各种潜在问题。DIBCO数据集包括灰度图、彩图、机器打印、手写文档、真实图像和模拟数据。DIBCO & H-DIBCO series:
- PLM(Palm Leaf Manuscripts)数据集是ICFHR2016手写文字图像分析竞赛的baseline数据集(数据集链接,直接点击下载READ dataset Bozen)。鉴于其特殊的物理特性和手稿的自身条件,该数据集对文档图像分析提出了新的挑战。棕榈叶手稿因老化、低对比度等产生脱色、被污染的部分;字体非常见,且字符之间、行与行之间的间距不同;字符形状的畸变和损坏都是显而易见的。一些常见的二值化算法无法在该数据集上得到令人满意的结果,它们通常会将不常见字符识别成噪声,因此这项任务需要采用特殊且具有适应性的二值化技术。
使用全卷积的二值化方法
Multi-Scale Fully Convolutional Neural Network 是Chris Tensmeyer 等人于 2017 年提出来的,利用多尺度全卷积神经网络对文档图像进行二值化,并在 DIBCO 和 PLM 这两个公开数据集上均取得了较好的结果。传统的全局或局部阈值忽略了像素点间的排列,边缘检测、马尔可夫随机场等方法对于前景的形状又存在很强的偏置,但是Fully Convolutional Network(FCN)能从训练数据中学习并挖掘出像素点在空间上的联系,而不是依赖于在局部形状上人工设置的偏置。
FCN模型的结构如下:

其他方法
Rupinder Kaur等人于2016年提出了基于形态学和阈值的文档图像二值化方法。该方法的实现可分为如下四步:
- 将RGB图像转化为灰度图
- 图像滤波处理
- 数学形态学运算
- 阈值计算
平滑去噪
空间滤波
由一个邻域和对该邻域内像素执行的预定义操作组成,滤波器中心遍历输入图像的每个像素点之后就得到了处理后的图像。每经过一个像素点,邻域中心坐标的像素值就替换为预定义操作的计算结果。若在图像像素上执行的是线性操作,则该滤波器称为线性空间滤波器,反之则称为非线性空间滤波器。
- 线性空间滤波器
- 平滑线性滤波:平滑线性滤波器的输出是包含在滤波器模板邻域内像素的简单平均值,因此也称为均值滤波器。
- 高斯滤波器:高斯滤波器的模板系数随着与模板中心距离的增大而减小。
- 非线性空间滤波器
- 中值滤波:非线性数字滤波器。首先对邻域内的值进行排序,中值作为输出。该滤波器消除椒盐噪声的效果比平滑线性空间滤波器更好。
- 双边滤波(Bilateral Filter):不仅如高斯滤波一样考虑到像素间的欧氏距离,还关注到像素范围域中的辐射差异(如像素与中心间的相似程度、颜色强度和深度距离等),这两个权重域分别称为:空间域(Spatial Domain S)和像素范围域(Range Domain R)。
小波阈值去噪
对于二维图像信号,可分别在水平和垂直的方向使用滤波器,从而实现二维小波多分辨率分解。
小波去噪的基本思路如下。
- 二维图像的小波分解。选择一个小波和小波分解的层次N,计算信号s到第N层的分解。
- 对高频系数进行阈值量化。对1~N的每一层选择阈值,并对该层的高频系数进行软阈值量化处理。阈值的选择是离散小波去噪中最关键的一步,阈值处理函数分为硬阈值和软阈值。
- 二维小波重构。根据小波分解第N层的低频系数和经过修改的第一到第N层的各层高频系数,计算二维信号的小波重构。
非局部方法
- NL-means: A. Buades 等人于 2005 年首次将 Non-Local 理论应用于图像去噪,提出了基于图像所有像素的非局部均值算法(NL-means)。
- BM3D(Block-Matching and 3D Filtering):是当前效果最好的算法之一。它与 NL-means算法具有相似之处在于同样运用到了非局部块匹配的思想,但其复杂度远高于 NL-means。BM3D包含两大步骤,每一步里又包括相似块分组、协同滤波和聚合。找到相似块后,不同于NL-means的均值处理,BM3D会对其做域转换操作,利用协同过滤以降低相似块自身的噪声,并在聚合阶段对相似块进行加权处理。
- 步骤一:基础估计(Basic Estimate)
- 相似块分组。首先在噪声图像中选择参照块,在参照块周围适当大小区域内进行搜索,寻找若干个差异度最小的块,与参照块一起整合成一个三维的矩阵。
- 协同滤波。先使用归一化的 3D 线性变换降低相似块中的噪声,再使用对应的反变换得到处理后的相似块。
- 聚合:对上一步处理后得到的相似快进行加权平均值操作得到目标块的像素值。
- 步骤二:最终估计(Final Estimate)
- 相似块分组。对步骤一初步处理后的图像,重新计算 L2 距离,得到相似块集合。
- 协同过滤。对第一步得到的相似块集合做域变换后,使用维纳收缩系数加权,再经过反变换得到新的集合
- 步骤一:基础估计(Basic Estimate)
基于神经网络的方法
- MLP
Harold Christopher Burger等人于2012年提出了使用多层感知机(Multi Layer Perceptron,MLP)实现图像去噪的思想,从而探讨深度学习在文字识别任务上是否有必要。整体的网络结构非常简单.
- LLNet
Kin Gwn Lore 等人于 2017 年提出了 The Low-Light Net(LLNet)的概念。LLNet通过引入序贯相似性检测算法(Stacked Sparse Denoising Autoencoder,SSDA)的思想实现低噪度图片的自适应增强(增亮、去噪)。
首先介绍一下自动编码机(Auto-Encoder,AE)。AE属于非监督学习,由三层网络组
成,其中输入层神经元数量与输出层神经元数量相等,中间层神经元数量少于输入层和输出层。对于每个训练样本,AE 学习的目的是使输出信号与输入信号尽可能相同。